Beyond “wrong output”
When a language model hallucinates, the surface-level observation is simple: it produces text that is incorrect, unsupported, or fabricated. But this description raises a deeper question: what is happening inside the model when it hallucinates?
One common intuition is that hallucination is random — a kind of noise or statistical accident in the token prediction process. Another is that it reflects gaps in training data. Both of these accounts may be partially right, but they are not mechanistic: they do not tell us where in the model the failure originates, or whether it corresponds to a detectable internal signal.
The Intelliton framework offers a different angle. Instead of treating hallucination as a property of the output, it treats it as a property of the internal dynamical trajectory during generation.
The central hypothesis is this:
Hallucination may correspond to a regime of weaker, less coherent, and more fragmented Intelliton activity — a trajectory that stays farther from the “grounded sector” of the model’s internal quasi-particle space.
This article explains the evidence for that hypothesis, focusing on Qwen3-4B-Base as the primary
example.
How hallucination is studied in the Intelliton framework
The module src/hallucination_diagnostic.py compares two types of prompts:
- Grounded prompts: questions that have factual, verifiable answers the model has likely encountered in training (for example, “What is the capital of France?”).
- Hallucination-prone prompts: questions designed to invite confabulation — factoid-sounding questions about obscure, ambiguous, or partially fabricated information that the model is likely to “fill in” plausibly but incorrectly.
For each prompt type, the analysis computes several internal metrics:
| Metric | What it measures |
|---|---|
| Singular-value spectrum divergence | How different the activation modes are from the grounded baseline |
| Coherence | How concentrated and stable the dominant singular modes are |
| Mode stability | Whether the dominant species remains consistent across generation steps |
| Entropy gap | How spread out the energy is across modes |
| Critical layers | Which layers show the largest divergence from grounded behaviour |
These metrics are computed during generation — step by step, as the model produces each new token — not just at the final output.
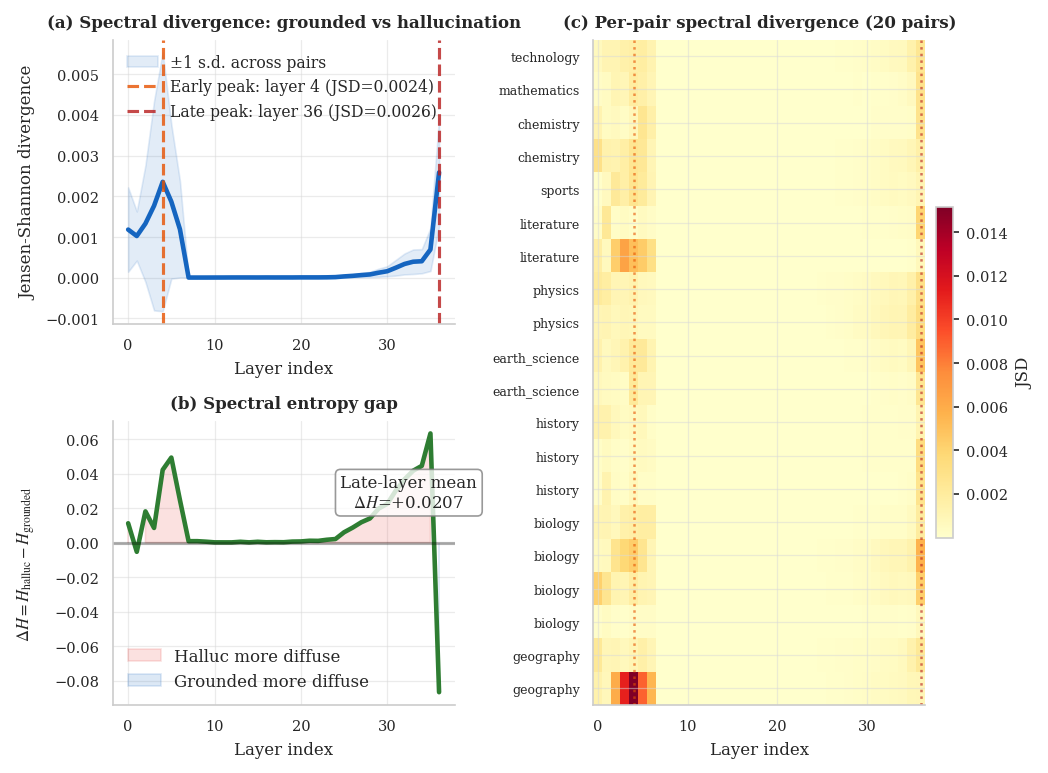 Hallucination diagnostics for Qwen3-4B-Base. The figure compares spectral signatures between
grounded and hallucination-prone prompts.
Hallucination diagnostics for Qwen3-4B-Base. The figure compares spectral signatures between
grounded and hallucination-prone prompts.
The trajectory evidence
The generation-time trajectory data provides the clearest picture. The file
intelliton_trajectory_summary.csv for Qwen3-4B-Base records, for each generation step and each
prompt type, the mean mode activation shift and the grounded deviation.
Grounded prompts: rising and coherent
For grounded factual prompts, the mean mode activation shift starts around 1.10 and rises to about 1.37 over the first 8 generation steps. Top species occupation also rises, from about 70.1% to 74.1%.
This means that as the model commits to a factual answer, the dominant Intelliton sector becomes stronger and more organised. The model is moving toward a more concentrated, coherent internal state.
Hallucination-prone prompts: weak and diverging
For hallucination-prone prompts, the picture is strikingly different.
The mean mode activation shift stays at only 0.32-0.41 throughout generation — roughly one third of the grounded value. The grounded deviation remains strongly negative (roughly -9 to -11 across most generation steps).
In plain language: hallucination-prone generation produces an internal trajectory that is both weaker in overall activation and farther from the grounded sector of Intelliton space.
The hallucination case is not just “wrong output at the end”. It is a persistently different internal state throughout the generation process.
Style prompts: the intermediate case
Stylistic continuation prompts — prompts asking the model to continue a piece of creative writing without strong factual constraints — occupy an intermediate position. Their activation shift is higher than hallucination-prone prompts but lower than grounded factual prompts.
This is a meaningful calibration check: style generation is not simply failure, but it is also not anchored to factual grounding. The Intelliton metric places it appropriately between the two extremes.
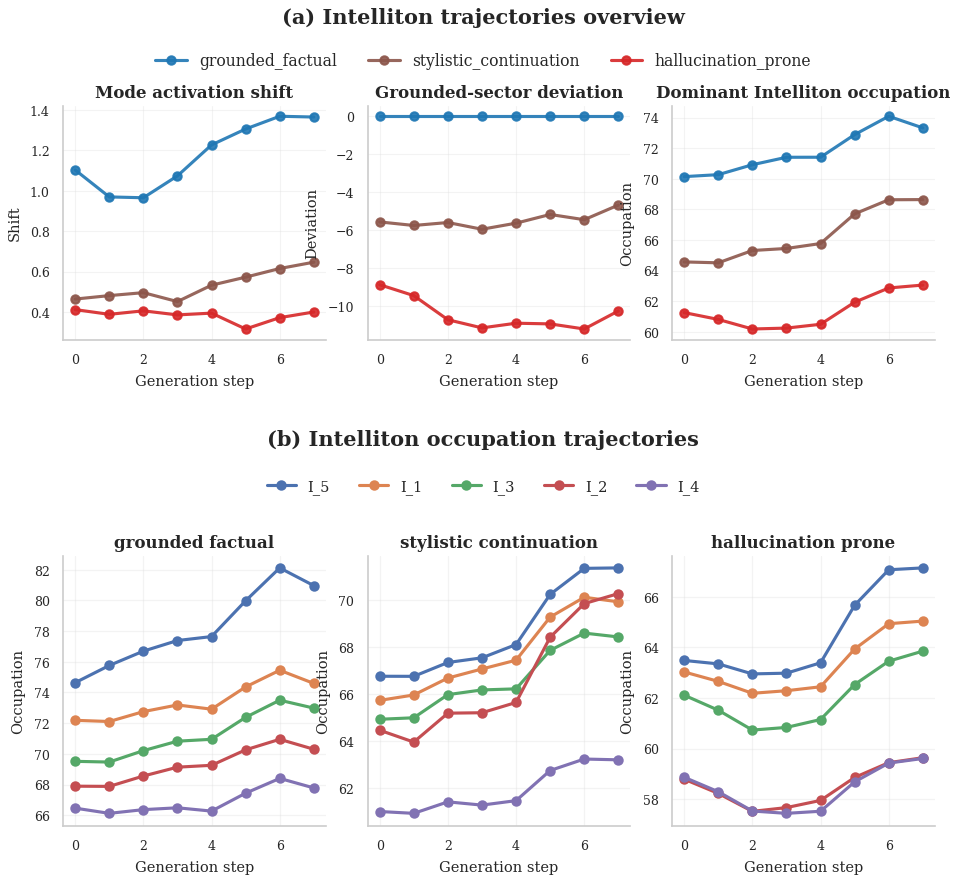 Generation-time Intelliton trajectories for Qwen3-4B-Base. Grounded (top), style (middle), and
hallucination-prone (bottom) prompts show qualitatively different internal dynamical profiles.
Generation-time Intelliton trajectories for Qwen3-4B-Base. Grounded (top), style (middle), and
hallucination-prone (bottom) prompts show qualitatively different internal dynamical profiles.
Transition graphs: which species dominate stable generation
The Intelliton transition graph shows which species transitions are most common during generation, and how strong those transitions are in terms of mode activation.
For grounded prompts in Qwen3-4B-Base, the dominant self-transitions are:
| Transition | Count | Mean target activation shift |
|---|---|---|
I_5 → I_5 |
110 | (strong) |
I_1 → I_1 |
13 | (moderate) |
I_2 → I_2 |
6 | (moderate) |
The generation stays largely within I_5 — the factual-recall species — with occasional excursions
into I_1 (logical reasoning) and I_2 (arithmetic).
For hallucination-prone prompts, I_5 → I_5 remains the most common transition, but its mean
target activation shift is much smaller. There is also more mixing among I_1, I_3, and I_5,
suggesting that the internal trajectory becomes more fragmented and less dominated by any single
species.
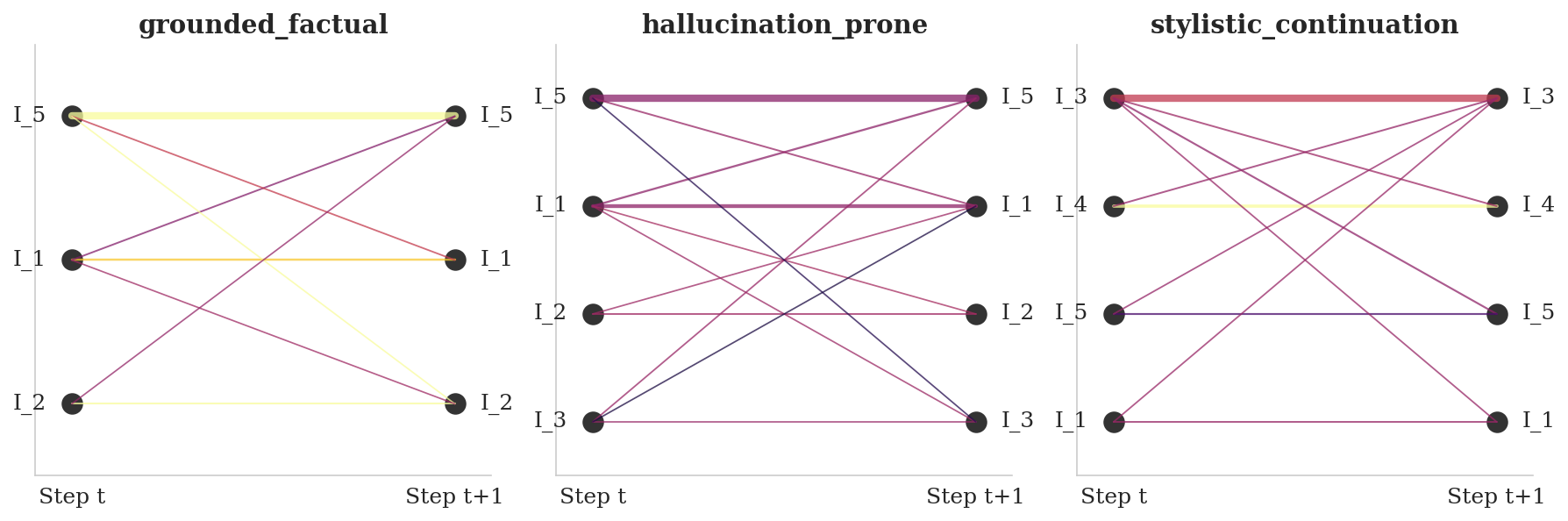 Species transition graph for Qwen3-4B-Base. Grounded generation is dominated by strong self-loops;
hallucination shows a weaker, more mixed pattern.
Species transition graph for Qwen3-4B-Base. Grounded generation is dominated by strong self-loops;
hallucination shows a weaker, more mixed pattern.
A multiple-failure-mode picture of hallucination
One of the most useful aspects of the Intelliton framework is that it suggests hallucination is not necessarily a single phenomenon. The trajectory data is consistent with at least four distinct failure modes:
- Grounded excitation decay: the leading Intelliton for factual tasks (here
I_5) fails to maintain its activation, causing the model to “lose grip” on the factual sector. - Species fragmentation: instead of a dominant self-loop, the trajectory becomes a mixture of several species without a clear attractor.
- Spectral broadening: the singular-value spectrum spreads out, indicating a loss of coherence in the dominant collective modes.
- Distance from grounded baseline: the trajectory drifts away from the region of Intelliton space that characterises correct factual generation.
Whether a given hallucination episode involves one or all four of these failure modes may depend on the specific model and the type of hallucination. But the framework gives us language and metrics for distinguishing them.
Implications and future directions
If this picture holds up under further investigation, it opens several practical possibilities.
Early warning signals
Since the deviation from grounded Intelliton trajectories is detectable at the very first generation steps, it is in principle possible to flag potential hallucinations before the full output is produced. This could be the basis for hallucination early warning systems.
Intervention on unstable species
If a particular species is identified as responsible for grounded, factual generation, it may be
possible to stabilise or amplify that species during inference using model steering techniques. The
codebase already includes modules such as src/gauge_intervention.py that hint at this direction.
Prompt strategies for grounded generation
If certain prompts consistently lead to strong grounded Intelliton trajectories, understanding their structure could inform better prompting strategies — ways to keep the model inside the grounded sector of its internal space.
Model comparison by internal stability
The Intelliton hallucination metric provides a new axis for comparing models — not just by accuracy
on a benchmark, but by the robustness and coherence of their internal factual-grounding sector. A
model with a stronger, more stable I_5-like species may be inherently more reliable for factual
tasks.
Caveats and open questions
As with all findings in this project, several important caveats apply.
The hallucination-prone prompts are designed, not naturally occurring. The distinction between “grounded” and “hallucination-prone” is imposed by the prompt design. In real-world use, the boundary is less clear.
Correlation is not causation. The Intelliton trajectory differences are associated with hallucination-prone prompts, but it has not yet been established that fixing the trajectory would prevent hallucination.
The pipeline has design choices. Different prompt sets, sequence lengths, and analysis parameters would produce different catalogs and possibly different conclusions.
The metric is relative, not absolute. The “grounded deviation” is measured relative to a baseline grounded trajectory. Its meaning depends on the quality of that baseline.
Despite these caveats, the structural pattern — grounded generation being internally stronger,
more coherent, and closer to a well-defined attractor — is consistent across all generation steps
and both task splits examined in Qwen3-4B-Base.
Where this series has taken us
This final article completes the four-part popular science series on Intellitons:
- What Are Intellitons? — The quasi-particle idea and why it might apply to transformers.
- Inside Qwen3-4B-Base — A detailed walkthrough of a model’s complete Intelliton catalogue.
- Scaling and Alignment — How parameter count and instruction tuning reshape the internal excitation spectrum.
- Hallucination as Internal Instability (this article) — Hallucination as a detectable internal dynamical regime.
The Intelliton framework is a young and exploratory research programme. But its outputs are concrete, its comparisons are reproducible, and its language is — at least arguably — more informative than treating language models as opaque statistical engines.
The goal is to develop a vocabulary that makes the internal life of neural networks legible. Whether Intellitons are ultimately the right vocabulary remains to be seen. But the evidence so far suggests they are pointing at something real.
Further reading
- Explore the full codebase at github.com/xiongzhp/Intelliton
- Read the accompanying technical paper (
intelliton_arxiv_paper.pdf) for the formal analysis - Return to Article 1: What Are Intellitons?
不只是“输出错了”
当语言模型出现幻觉时,表层观察很简单:它生成了错误、缺乏依据,甚至纯属捏造的文本。但 这个描述会引出更深一层的问题:模型在幻觉发生时,内部到底发生了什么?
一种常见直觉认为,幻觉是随机噪声,是 token 预测过程里的统计偶然;另一种看法则认为,幻 觉主要反映训练数据的缺口。两者都可能部分正确,但都不够“机制化”:它们并没有告诉我们, 故障究竟起源于模型的哪里,是否对应某种可检测的内部信号。
Intelliton 框架提供了不同角度。它不把幻觉看作输出属性,而是把它看作生成过程中的 内部动力学轨迹 属性。
核心假设可以概括为:
幻觉可能对应一种更弱、更不相干、也更碎片化的 Intelliton 活动区间,也就是一条离模型 “grounded 扇区”更远的内部准粒子轨迹。
这篇文章会围绕 Qwen3-4B-Base 解释支撑这一假设的证据。
在 Intelliton 框架里,幻觉是怎么研究的
src/hallucination_diagnostic.py 这个模块比较两类提示词:
- Grounded prompts:答案有事实依据、可验证,而且模型大概率在训练中见过的问题,例如 “法国的首都是哪里?”
- Hallucination-prone prompts:专门设计来诱发编造的问题,也就是那些听上去像事实问答、 但内容冷门、歧义大,甚至部分虚构的问题。模型很可能会“顺着语气补全”,却补出错误答案。
对每类提示词,分析会计算多种内部指标:
| 指标 | 含义 |
|---|---|
| 奇异值谱散度 | 激活模式与 grounded 基线相比有多不同 |
| 相干性 | 主导奇异模态有多集中、多稳定 |
| 模式稳定性 | 主导物种能否在生成步之间保持一致 |
| 熵差 | 能量在不同模式之间分散得有多开 |
| 关键层 | 哪些层偏离 grounded 行为最明显 |
这些量是在 生成过程中 逐步计算的,也就是模型每产生一个新 token 就更新一次,而不是只 在最终输出后才做分析。
Qwen3-4B-Base 的幻觉诊断图,对比了 grounded 与 hallucination-prone 提示词的谱特征。
轨迹证据:最清楚的图像
生成期轨迹数据给出了最直观的画面。Qwen3-4B-Base 的 intelliton_trajectory_summary.csv
记录了每个生成步、每种提示词类型下的平均模式激活位移和 grounded deviation。
Grounded 提示词:逐步增强而且更相干
对 grounded 的事实型提示词,平均模式激活位移从大约 1.10 起步,在前 8 个生成步骤里上 升到 1.37 左右。主导物种占据度也同步上升,从大约 70.1% 提升到 74.1%。
这意味着,当模型逐渐锁定一个有事实依据的答案时,主导的 Intelliton 扇区会变得 更强、更 有组织。模型正在向一个更集中、更相干的内部状态收敛。
Hallucination-prone 提示词:更弱,而且持续偏离
对容易诱发幻觉的提示词,图景就完全不同了。
平均模式激活位移在整个生成过程中只维持在 0.32 到 0.41 之间,大约只有 grounded 情况 的三分之一。与此同时,grounded deviation 始终保持明显负值,大致在 -9 到 -11 之间。
用直白的话说:幻觉倾向型生成对应的是一条内部轨迹,它既 整体激活更弱,也 离 grounded 扇区更远。
重要的是,这并不只是“最后一句答错了”。从生成一开始,内部状态就已经持续表现为另一种 动力学区间。
风格续写:位于中间地带
如果提示词是风格化续写,也就是要求模型继续写一段创意文本,而不是给出事实答案,那么它 的激活位移会处在 grounded 与 hallucination-prone 之间。
这是一个很有意义的校准结果:风格续写并不等于失败,但它也不被事实 grounding 锚定。 Intelliton 指标把它合理地放在了两极之间。
Qwen3-4B-Base 的生成期 Intelliton 轨迹。grounded(上)、style(中)与 hallucination-prone
(下)提示词呈现出定性上不同的内部动力学轮廓。
转移图:稳定生成由哪些物种主导
Intelliton 转移图展示的是:生成过程中哪些物种之间的跃迁最常见,以及这些跃迁对应的模式激 活有多强。
对 Qwen3-4B-Base 的 grounded 提示词,最主要的自跃迁是:
| 转移 | 次数 | 目标激活平均位移 |
|---|---|---|
I_5 → I_5 |
110 | (强) |
I_1 → I_1 |
13 | (中等) |
I_2 → I_2 |
6 | (中等) |
也就是说,生成过程大部分时间都停留在 I_5,也就是事实回忆物种中,只偶尔偏向 I_1
(逻辑推理)和 I_2(算术)。
而对 hallucination-prone 提示词 来说,虽然 I_5 → I_5 仍然是最常见跃迁,但它的平均
目标激活位移小得多。同时 I_1、I_3、I_5 之间的混合也更多,说明内部轨迹更碎片化,更
缺乏单一主导吸引子。
Qwen3-4B-Base 的物种转移图。grounded 生成主要由强自环主导;hallucination 则更弱、更混杂。
幻觉可能不是单一失败,而是多种失败模式
Intelliton 框架最有价值的一点是,它暗示幻觉不一定是一种单一现象。轨迹数据至少与四种不同 失败模式相符合:
- Grounded 激发衰减:负责事实任务的主导 Intelliton(这里是
I_5)没能维持激活,模 型因此“失去对事实扇区的抓握”; - 物种碎片化:不再有强主导自环,轨迹变成多个物种的混合,缺乏清晰吸引子;
- 谱展宽:奇异值谱被摊得更开,意味着主导集体模式失去相干性;
- 偏离 grounded 基线:轨迹持续漂离正确事实生成所对应的 Intelliton 空间区域。
一次具体的幻觉事件到底会涉及其中一种还是全部几种,可能依赖于模型本身以及幻觉类型。但 至少这个框架为区分这些情况提供了语言和指标。
含义与后续方向
如果这幅图景在进一步研究中站得住脚,它会带来一些实际可能性。
早期预警信号
既然偏离 grounded Intelliton 轨迹的信号在生成最初几个步骤就能被检测到,那么原则上就可以 在完整输出形成之前,提前标记潜在幻觉。这可以成为幻觉早期预警系统的基础。
对不稳定物种进行干预
如果某个物种被识别为 grounded 事实生成的关键承担者,那么就可能通过推理时的模型 steering
技术去稳定或放大它。代码库中像 src/gauge_intervention.py 这样的模块,已经在暗示这一方向。
面向 grounded 生成的提示策略
如果某些提示词结构更容易产生强 grounded Intelliton 轨迹,那么理解这些结构,就可能帮助我 们设计更好的 prompting 策略,让模型尽量停留在 grounded 扇区内部。
从内部稳定性比较模型
Intelliton 幻觉指标提供了比较模型的新轴线。我们不只比较基准分数,也可以比较模型内部事实
grounding 扇区的稳健性和相干性。一个拥有更强、更稳定 I_5 型物种的模型,可能天然更适合
事实任务。
注意事项与开放问题
和项目里的其他结果一样,这些发现也有几条重要限定。
Hallucination-prone 提示词是人为设计的,不是自然收集的。 “grounded” 与 “hallucination-prone” 的区分是通过提示词设计施加进去的。在真实使用场景中,这条边界不会 这么清晰。
相关不等于因果。 Intelliton 轨迹差异与幻觉倾向有关联,但目前还不能说:只要修复轨迹, 就一定能防止幻觉。
分析流程本身带有设计选择。 不同的提示词集合、序列长度和分析参数,可能会给出不同的 目录,也可能带来不同结论。
这是相对指标,而不是绝对指标。 “grounded deviation” 是相对于一个 grounded 基线定义 出来的,它的含义依赖于基线本身的质量。
尽管如此,有一个结构性模式是清楚的:grounded 生成在内部上更强、更相干,也更靠近一个清晰
的吸引子。这个模式在 Qwen3-4B-Base 的所有生成步和两类任务划分中都能稳定看到。
这一系列把我们带到了哪里
这篇文章为 Intelliton 四篇科普系列收尾:
- 什么是 Intelliton?:介绍准粒子想法, 以及它为什么可能适用于变换器;
- 走进 Qwen3-4B-Base:完整 讲解一个模型的 Intelliton 目录;
- 规模扩展与对齐:说明参数规 模和指令微调如何重塑内部激发谱;
- 把幻觉理解为内部不稳定性(本文):把幻觉看作一种可检测的内部动力学区间。
Intelliton 框架仍然很年轻,也带有探索性质。但它的输出是具体的、比较是可复现的,而它提供 的语言,至少在目前看来,比“把语言模型当作黑箱统计机器”要更有解释力。
项目的目标,是发展出一套能让神经网络内部生命变得可读的词汇。Intelliton 最终是不是这套词 汇,还需要时间验证。但到目前为止,证据至少说明:它指向了一些真实存在的结构。
延伸阅读
- 访问完整代码库:github.com/xiongzhp/Intelliton
- 阅读配套技术论文
intelliton_arxiv_paper.pdf获取更形式化的分析 - 返回 第 1 篇:什么是 Intelliton?