Two of the biggest questions in LLM science
Two of the most discussed phenomena in large language model research are scaling and alignment. Scaling means training bigger models; alignment (here: instruction tuning) means fine-tuning a model to follow instructions and behave helpfully.
Both interventions are known to improve benchmark performance. But do they change the internal structure of the model? Do they reshape the quasi-particle spectrum?
The Intelliton analysis of five models — Qwen3-4B-Base, Qwen3-4B, Qwen3-8B-Base, Qwen3-8B,
and Mistral-7B-v0.3 — provides a concrete, data-driven answer.
Base versus Instruct: what alignment does
The clearest comparison is between a base model and its instruction-tuned counterpart in the same family.
Qwen3-4B-Base vs. Qwen3-4B
| Property | Qwen3-4B-Base | Qwen3-4B |
|---|---|---|
| Number of species | 6 | 5 |
I_0 amplitude |
6167.1 | 6562.4 |
| Dominant momentum | k ≈ π | k ≈ 1.885 |
| Secondary momenta | k ≈ 0 | k ≈ 1.885 (shared) |
| Fixed-point types | IR + crossover | all crossover |
| Grounded profile mean | 32.68 | 29.13 |
The most striking difference is in momentum structure.
In Qwen3-4B-Base, the dominant mode I_0 peaks at k ≈ π (high frequency, alternating pattern),
while the five secondary modes all peak near k ≈ 0 (low frequency, global pattern). There is a
clean split.
In Qwen3-4B (the instruction-tuned version), the dominant mode shifts to k ≈ 1.885, and the
secondary modes also cluster around the same momentum. The model becomes more homogeneous in
its momentum structure. The clean split between backbone and task-specific modes disappears.
The fixed-point type change is equally telling. In the base model, five of the six species are
labelled IR (settled, stable), while I_0 is crossover (still transitioning). In the
instruct model, all species are labelled crossover. Alignment appears to push the model’s
collective modes into a more uniformly active, less settled dynamical regime.
One possible interpretation:
Instruction tuning compresses or reorganises the internal excitation landscape into a more uniform effective regime. The spectral diversity that exists in the base model is partially smoothed out, and more modes are kept in a dynamically transitional state.
This does not mean instruction tuning is worse. It may mean the model’s degrees of freedom are being regularised toward instruction-following behaviour, possibly at the cost of some internal differentiation.
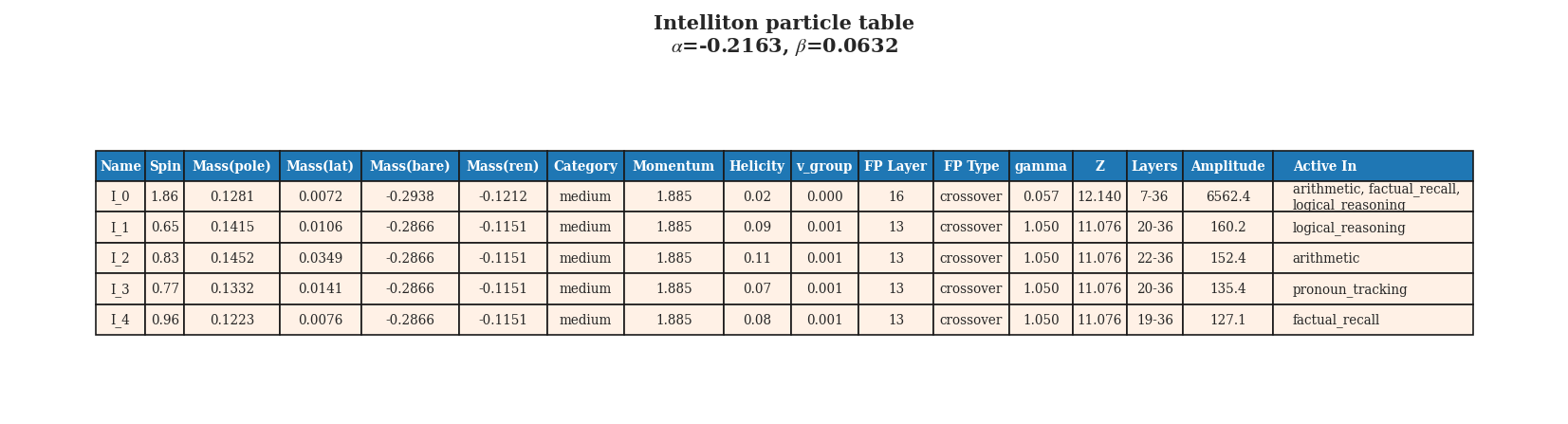 The Intelliton catalogue for Qwen3-4B (instruction-tuned). Compare with Qwen3-4B-Base to see
the homogenisation of momentum structure.
The Intelliton catalogue for Qwen3-4B (instruction-tuned). Compare with Qwen3-4B-Base to see
the homogenisation of momentum structure.
Scaling from 4B to 8B: what more parameters do
The next comparison holds model family (Qwen3) and training type (base) constant and varies the parameter count.
Qwen3-4B-Base vs. Qwen3-8B-Base
| Property | Qwen3-4B-Base | Qwen3-8B-Base |
|---|---|---|
| Number of species | 6 | 7 |
I_0 amplitude |
6167.1 | 7908.4 |
| Dominant momentum | k ≈ π | k ≈ π |
| Grounded profile mean | 32.68 | 60.26 |
| Grounded-hallucination separation | moderate | larger |
The 8B model has one more species. Its leading mode I_0 is 28% stronger in amplitude.
Most strikingly, the grounded generation profile mean nearly doubles (32.68 → 60.26).
In Intelliton terms, scaling up does not simply add more parameters uniformly. It appears to amplify the dominant dynamical sectors of the model, making the leading quasi-particle modes substantially stronger and the grounded generation trajectory more sharply defined.
The momentum structure is also richer in the 8B model. While the leading mode still peaks at k ≈ π, many of the secondary species cluster around k ≈ 1.885 rather than strictly k ≈ 0. This suggests that intermediate-scale spatial organisation becomes more visible as the model grows.
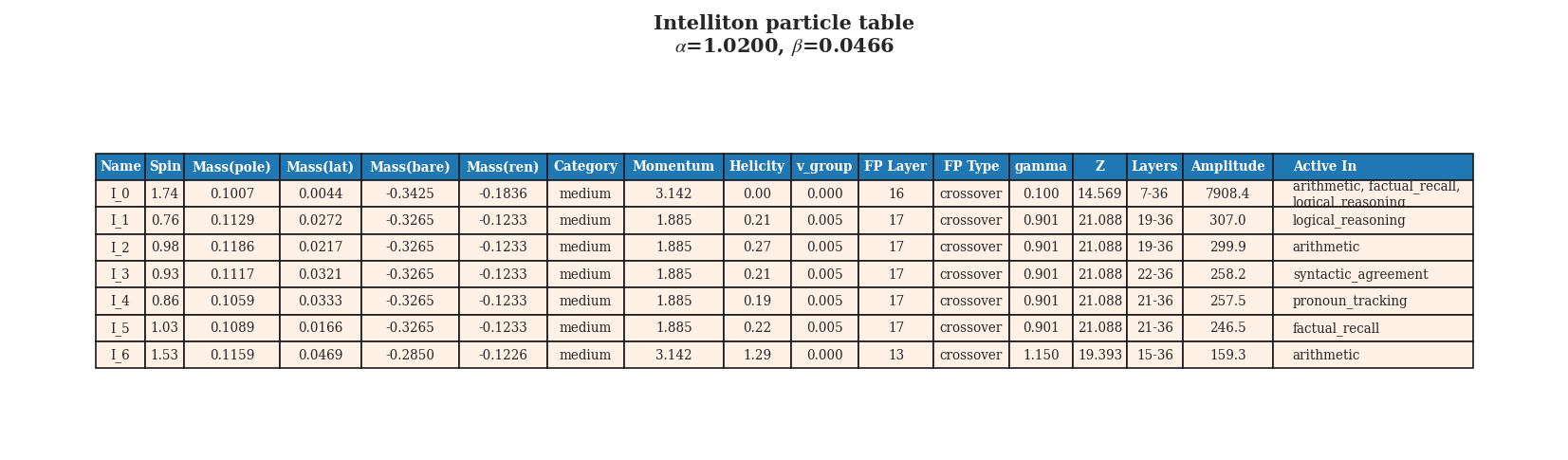 The Intelliton catalogue for Qwen3-8B-Base. The leading mode is stronger, and the species set
is slightly larger compared with Qwen3-4B-Base.
The Intelliton catalogue for Qwen3-8B-Base. The leading mode is stronger, and the species set
is slightly larger compared with Qwen3-4B-Base.
Scaling plus alignment: Qwen3-8B
When both scaling and instruction tuning are applied — Qwen3-8B — the results follow the pattern
suggested by the two effects separately.
| Property | Qwen3-8B-Base | Qwen3-8B |
|---|---|---|
| Number of species | 7 | 6 |
I_0 amplitude |
7908.4 | ~7600 |
| Grounded profile mean | 60.26 | 57.14 |
| Fixed-point types | mixed | more crossover |
Instruction tuning at 8B scale slightly reduces the species count (7 → 6) and slightly lowers the dominant mode amplitude and grounded profile mean, consistent with the homogenisation effect seen at 4B scale. But the 8B instruct model remains far stronger than the 4B models in its grounded trajectory profile.
The combined takeaway is clean:
- Scaling to 8B increases the strength of dominant collective modes and sharpens the grounded generation signal.
- Instruction tuning slightly compresses or regularises that internal structure, reducing species count and reducing the grounded-hallucination separation.
These two effects appear to be largely independent and roughly additive in their impact on the Intelliton spectrum.
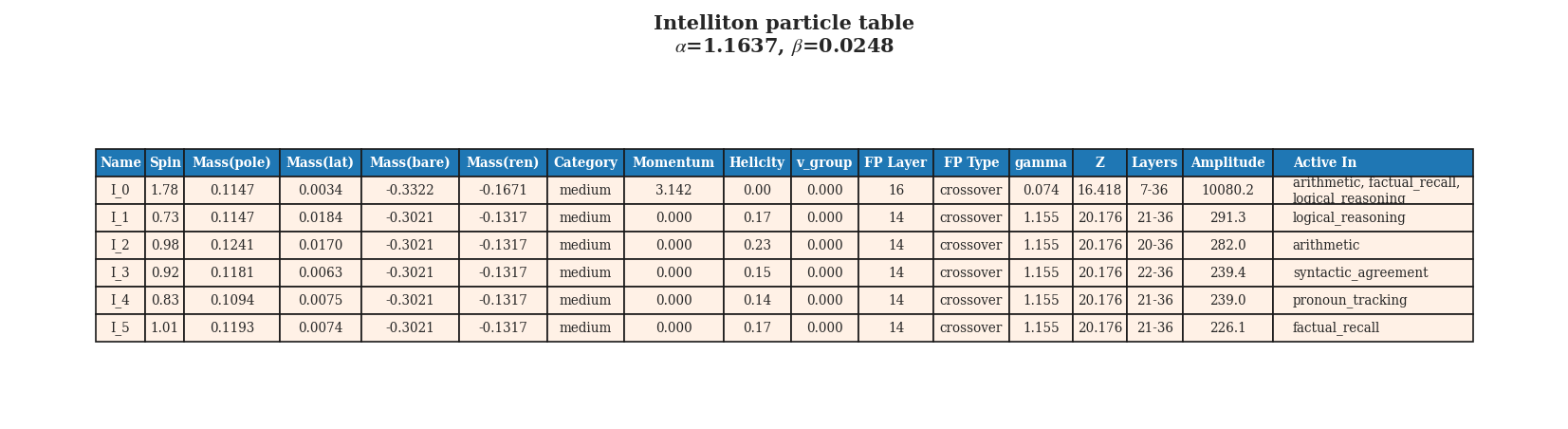 The Intelliton catalogue for Qwen3-8B (instruction-tuned 8B model).
The Intelliton catalogue for Qwen3-8B (instruction-tuned 8B model).
A completely different family: Mistral-7B-v0.3
The most dramatic contrast in the entire comparison set comes from Mistral-7B-v0.3, a 7B model
from a different architecture family.
| Property | Qwen3-4B-Base | Mistral-7B-v0.3 |
|---|---|---|
| Number of species | 6 | 25 |
I_0 amplitude |
6167.1 | 249.4 |
| Grounded profile mean | 32.68 | 21.48 |
| Grounded profile std | moderate | 46.56 (very large) |
| Fixed-point types | IR + crossover | UV + IR + crossover |
Under the same analysis pipeline, Mistral produces 25 species — more than four times as many as any Qwen model. This is a striking result.
The leading species I_0 in Mistral has an amplitude of only 249.4, compared with 6167 in
Qwen3-4B-Base. In other words, the Mistral model does not have a strongly dominant backbone
excitation. Its collective mode landscape is much more fragmented: many modes of comparable
strength, rather than one overwhelming mode with several weak followers.
Mistral also shows UV-labelled species — modes that remain in a fine-grained, ultraviolet-like dynamical state throughout the network, rather than flowing toward infrared stability. This suggests a more persistent fine-grained structure in Mistral’s layers compared with Qwen.
The generation dynamics also differ. The grounded profile mean for Mistral (21.48) is lower than for all Qwen models, and the standard deviation (46.56) is much larger. The Intelliton metric, calibrated using Qwen, describes Mistral’s trajectory space as much noisier and more turbulent.
One interpretation:
Qwen organises its internal computation around a few very strong collective modes. Mistral spreads the load more broadly across many smaller modes. Under this analysis, they have genuinely different “particle physics” inside.
Whether this difference reflects architectural choices, training data, training procedure, or some combination is an open question. But the Intelliton framework makes the difference visible and measurable.
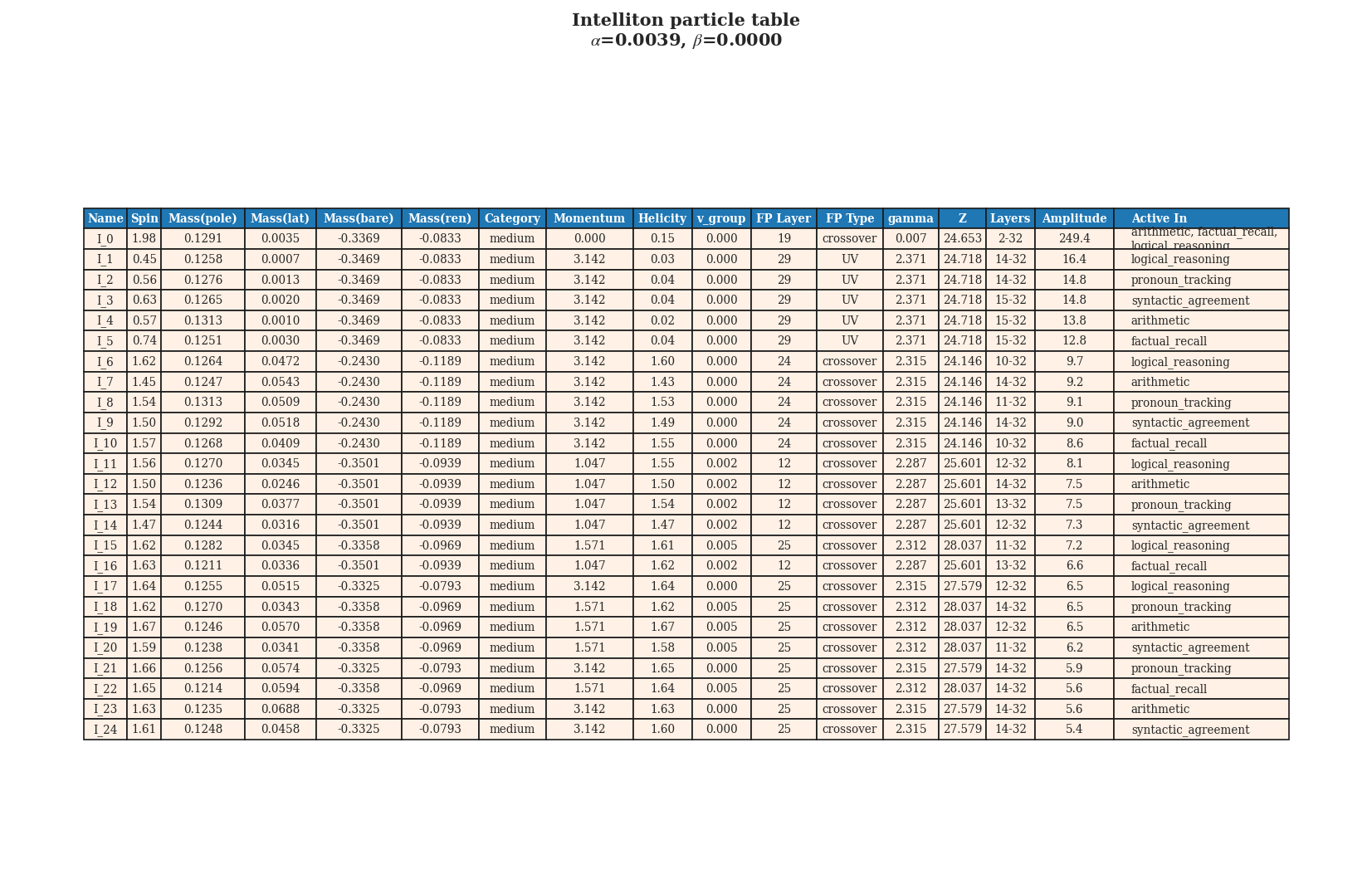 The Intelliton catalogue for Mistral-7B-v0.3. Twenty-five species, a far more fragmented landscape
than any Qwen model.
The Intelliton catalogue for Mistral-7B-v0.3. Twenty-five species, a far more fragmented landscape
than any Qwen model.
A summary table
| Model | Species | I_0 Amplitude |
Momentum structure | Fixed-point types | Grounded mean |
|---|---|---|---|---|---|
| Qwen3-4B-Base | 6 | 6167 | π + 0 (split) | IR + crossover | 32.68 |
| Qwen3-4B | 5 | 6562 | 1.885 (homogeneous) | all crossover | 29.13 |
| Qwen3-8B-Base | 7 | 7908 | π + 1.885 (richer) | mixed | 60.26 |
| Qwen3-8B | 6 | ~7600 | 1.885 (homogeneous) | more crossover | 57.14 |
| Mistral-7B-v0.3 | 25 | 249 | fragmented | UV + IR + crossover | 21.48 |
Conclusions
The Intelliton comparison across these five models yields several clear empirical regularities:
- Instruction tuning homogenises the momentum structure and shifts more species into crossover regimes, reducing internal spectral diversity.
- Scaling from 4B to 8B strengthens the dominant dynamical sectors, producing a more strongly occupied and more sharply separated Intelliton landscape.
- Different model families can have qualitatively different internal spectra — Qwen is dominated by a few strong modes, Mistral is more fragmented and UV-rich.
- The Intelliton framework provides a vocabulary for these differences that goes beyond benchmark accuracy or parameter count alone.
The next article turns to one of the most practically important applications of this framework: using the Intelliton lens to study hallucination — and asking whether internal spectral instability can be a diagnostic signal for when a model is about to confabulate.
Further reading
- Continue to Article 4: Hallucination as Internal Instability
- Return to Article 2: Inside Qwen3-4B-Base
- Return to Article 1: What Are Intellitons?
LLM 科学里最重要的两个问题
在大语言模型研究中,讨论最多的两个现象就是 规模扩展 和 对齐。规模扩展指训练更大 的模型;对齐在这里主要指指令微调,也就是把模型微调得更会遵循指令、更像一个“有帮助的 助手”。
这两种干预都已知能提升基准性能。但它们会不会改变模型的 内部结构?会不会改写它的准粒 子谱?
对五个模型的 Intelliton 分析,也就是 Qwen3-4B-Base、Qwen3-4B、Qwen3-8B-Base、
Qwen3-8B 和 Mistral-7B-v0.3,给出了一个具体、数据驱动的回答。
Base 对 Instruct:对齐到底做了什么
最直接的比较,是把同一家族里的基础模型与对应的指令微调版本放在一起。
Qwen3-4B-Base vs. Qwen3-4B
| 属性 | Qwen3-4B-Base | Qwen3-4B |
|---|---|---|
| 物种数量 | 6 | 5 |
I_0 振幅 |
6167.1 | 6562.4 |
| 主导动量 | k ≈ π | k ≈ 1.885 |
| 次级动量 | k ≈ 0 | k ≈ 1.885(共享) |
| 固定点类型 | IR + crossover | 全部为 crossover |
| grounded 轨迹均值 | 32.68 | 29.13 |
最突出的差异在于 动量结构。
在 Qwen3-4B-Base 中,主导模式 I_0 位于 k ≈ π,也就是高频交替模式;而五个次级模式都位
于 k ≈ 0,也就是低频、较全局的模式。两者之间有很干净的分裂。
在 Qwen3-4B 这个指令微调版本里,主导模式移到了 k ≈ 1.885,次级模式也集中在同样的动量
附近。模型的动量结构变得更 同质化,原本骨干模态与任务模态之间清晰的分裂消失了。
固定点类型的变化同样耐人寻味。在基础模型里,六个物种中的五个是 IR,表示已经稳定下
来;只有 I_0 属于 crossover,还在过渡。到了 instruct 模型,所有 物种都变成了
crossover。这意味着对齐似乎把模型的集体模式推向一个更统一、更活跃、也更不完全稳定
的动力学区间。
一种可能的解释是:
指令微调把内部激发景观压缩或重组进了一个更均匀的有效区间。基础模型里原本存在的谱多 样性被部分抹平,更多模式被维持在动态过渡状态。
这并不意味着指令微调更差。更合理的理解是:模型的自由度被正则化到更偏向指令遵循的行为 上,而代价可能是内部结构的一部分区分度下降。
Qwen3-4B(指令微调版)的 Intelliton 目录。与 Qwen3-4B-Base 对照,可以清楚看到动量结构
的同质化。
从 4B 扩到 8B:更多参数带来了什么
下一组比较固定模型家族(Qwen3)和训练类型(base),只改变参数规模。
Qwen3-4B-Base vs. Qwen3-8B-Base
| 属性 | Qwen3-4B-Base | Qwen3-8B-Base |
|---|---|---|
| 物种数量 | 6 | 7 |
I_0 振幅 |
6167.1 | 7908.4 |
| 主导动量 | k ≈ π | k ≈ π |
| grounded 轨迹均值 | 32.68 | 60.26 |
| grounded 与 hallucination 的分离度 | 中等 | 更大 |
8B 模型多出了一个物种,而它的主导模式 I_0 振幅也 增强了 28%。更显著的是,grounded
生成轨迹的均值几乎 翻倍(32.68 → 60.26)。
用 Intelliton 的语言来说,规模扩展并不是简单地给模型“均匀加参数”,而更像是在 放大主导动力学扇区,让领先的准粒子模式更强,同时让 grounded 生成轨迹更清晰、更稳定。
8B 模型的动量结构也更丰富。虽然主导模式仍然位于 k ≈ π,但很多次级物种集中在 k ≈ 1.885, 而不再严格卡在 k ≈ 0。这暗示着,随着模型变大,中等尺度的空间组织结构开始更明显地浮现。
Qwen3-8B-Base 的 Intelliton 目录。相比 Qwen3-4B-Base,领先模式更强,物种集合也略大。
规模扩展加上对齐:Qwen3-8B
当规模扩展和指令微调同时发生时,也就是 Qwen3-8B,结果大体延续了前两种效应各自的趋向。
| 属性 | Qwen3-8B-Base | Qwen3-8B |
|---|---|---|
| 物种数量 | 7 | 6 |
I_0 振幅 |
7908.4 | ~7600 |
| grounded 轨迹均值 | 60.26 | 57.14 |
| 固定点类型 | 混合 | 更多 crossover |
在 8B 规模下,指令微调让物种数略微下降(7 → 6),同时稍微降低了主导模式振幅和 grounded 轨迹均值,这与 4B 上观察到的同质化趋势是一致的。但即便如此,8B instruct 模型在 grounded 轨迹上的强度仍然明显高于所有 4B 模型。
合在一起看,结论很清楚:
- 扩展到 8B 会增强主导集体模式,并让 grounded 生成信号更尖锐;
- 指令微调 会略微压缩或正则化这种内部结构,减少物种数量,并缩小 grounded 与 hallucination 之间的间隔。
这两个效应在 Intelliton 谱上的影响看起来大致相互独立,而且近似可叠加。
Qwen3-8B(8B 指令微调版)的 Intelliton 目录。
完全不同的家族:Mistral-7B-v0.3
整个对比集中最戏剧性的差异,来自 Mistral-7B-v0.3,一个属于完全不同架构家族的 7B 模型。
| 属性 | Qwen3-4B-Base | Mistral-7B-v0.3 |
|---|---|---|
| 物种数量 | 6 | 25 |
I_0 振幅 |
6167.1 | 249.4 |
| grounded 轨迹均值 | 32.68 | 21.48 |
| grounded 轨迹标准差 | 中等 | 46.56(非常大) |
| 固定点类型 | IR + crossover | UV + IR + crossover |
在相同分析管线下,Mistral 产生了 25 个物种,是任一 Qwen 模型的四倍以上。这是非常醒目 的结果。
Mistral 的领先物种 I_0 振幅只有 249.4,而 Qwen3-4B-Base 中对应值是 6167。换句话说,
Mistral 并没有一个压倒性的骨干激发。它的集体模式景观更加 碎片化:很多模式强度彼此接
近,而不是一个特别强、后面跟着几条弱尾巴。
Mistral 还出现了 UV 型物种,也就是那些在整个网络中都保持细粒度、紫外式动力学状态, 而不会流向红外稳定的模式。这表明,相比 Qwen,Mistral 的层内细粒度结构保留得更久。
生成动力学也不同。Mistral 的 grounded 轨迹均值(21.48)低于所有 Qwen 模型,而标准差 (46.56)则大得多。以 Qwen 为标定的 Intelliton 指标会把 Mistral 的轨迹空间描述为更嘈杂、 更湍动。
一种可能的总结是:
Qwen 把内部计算组织在少数几个极强的集体模式周围;Mistral 则把负载分散到许多较小模 式上。从这个分析看,它们内部确实像拥有不同的“粒子物理学”。
这种差异到底来自架构、训练数据、训练流程,还是多种因素叠加,目前仍是开放问题。但 Intelliton 框架至少把这种差异清晰地呈现并量化了出来。
Mistral-7B-v0.3 的 Intelliton 目录。共 25 个物种,比任何 Qwen 模型都碎片化得多。
汇总表
| 模型 | 物种数 | I_0 振幅 |
动量结构 | 固定点类型 | grounded 均值 |
|---|---|---|---|---|---|
| Qwen3-4B-Base | 6 | 6167 | π + 0(分裂) | IR + crossover | 32.68 |
| Qwen3-4B | 5 | 6562 | 1.885(同质) | 全部 crossover | 29.13 |
| Qwen3-8B-Base | 7 | 7908 | π + 1.885(更丰富) | 混合 | 60.26 |
| Qwen3-8B | 6 | ~7600 | 1.885(同质) | 更多 crossover | 57.14 |
| Mistral-7B-v0.3 | 25 | 249 | 碎片化 | UV + IR + crossover | 21.48 |
结论
这五个模型的 Intelliton 对比给出了几条相当清楚的经验规律:
- 指令微调会同质化动量结构,并把更多物种推入 crossover 区间,从而降低内部谱多样性;
- 从 4B 扩展到 8B 会强化主导动力学扇区,形成占据更强、分离更清晰的 Intelliton 景观;
- 不同模型家族可以拥有定性上非常不同的内部谱:Qwen 由少数强模式主导,Mistral 则更 碎片化,也更偏 UV;
- Intelliton 框架为这些差异提供了一套超越基准分数和参数规模的描述语言。
下一篇文章会把这个框架用于一个更直接的应用问题:幻觉。我们将问,内部谱不稳定性是否 能成为模型即将开始“编造”的诊断信号。